双非大学生,涌入大厂AI流水线
AI焦虑已经从大厂渗透进了大学这座象牙塔。在一片“被替代”的忧惧声中,一群来自非北上广深、非985高校的大学生,主动跳进了这股浪潮——他们不是来做实习的,是来兼职“拧螺丝”的,拧的是AI大模型的螺丝。
AI焦虑已经从大厂渗透进了大学这座象牙塔。在一片“被替代”的忧惧声中,一群来自非北上广深、非985高校的大学生,主动跳进了这股浪潮——他们不是来做实习的,是来兼职“拧螺丝”的,拧的是AI大模型的螺丝。
MemMachine是MemVerge公司开发的开源AI记忆系统,专为AI大模型和智能体设计,能像人脑一样存储和回忆交互数据,解决AI“无状态失忆”问题。采用分层架构(短期记忆、长期记忆、用户画像),支持跨模型调用,准确率达92.34%,在LOCOMO基准测试中以84.87%得分领先行业。其技术已应用于医疗陪护等场景,可拦截83%用药错误,并计划拓展至2030年达284.5亿美元的AI记忆市场。企业版提供安全合规的商用方案,开源项目可通过GitHub获取
Mistral 3是Mistral AI发布开源的最新多模态大模型系列,包含旗舰模型Mistral Large 3(675B总参数)和轻量版Ministral系列(3B/8B/14B),均支持图像理解与多语言处理,采用Apache 2.0协议开源。其中Mistral Large 3在开源模型中性能排名前列,Ministral系列以高性价比著称,14B推理版本在AIME 2025测试中准确率达85%。特别适配边缘设备部署,兼顾企业级应用需求,如智能客服和数据分析。
GigaWorld-0是国内具身智能创业公司极佳视界(GigaAI)开源的世界模型框架,主要用于解决具身智能(Embodied AI)领域的数据瓶颈问题。高效生成高质量、多样化且物理真实的训练数据,推动具身 AI 的发展。包含两个核心组件:GigaWorld-0-Video 和 GigaWorld-0-3D。前者通过大规模视频生成技术,精细控制环境外观、摄像机视角和动作语义,生成纹理丰富、时间连贯的具身交互视频序列;后者结合 3D 建模、高斯点绘制重建、物理可微系统辨识和运动规划,确保数据的几何一致性和物理真实性。
Vidi2是字节跳动开源的第二代多模态视频理解与生成大模型,专注于视频内容的理解、分析和创作。支持文本、视频、音频三种模态的联合输入,能同时理解画面内容、声音信息以及自然语言指令,实现跨模态的交互与推理。可精准定位视频中特定事件或目标对象的时间范围和空间位置,模型能自动标注出对应的时间段和画面中的目标区域,误差可精确到毫秒级。能处理数小时长的原始视频素材,快速检索出符合特定语义的片段。
人工智能正以前所未有的速度重塑科学研究版图。众多科研领域中,生命科学、生物医药等生物学领域凭借数据丰富、应用场景明确、社会需求迫切等因素,成为AI+科学研究(以下简称 科学智 能)最活跃、最具引领性的前沿阵地。AI模型和工具不仅在预测蛋白质结构等基础研究上取得突破,更在推动全新药物管线进入临床试验,甚至开始自主发现新的生物学通路 。
自ChatGPT发布以来(2022年11月30日),美股和全球主要股市迎来了一轮AI浪潮。截止到2025年12月2日,道琼斯指数、标普500指数、纳斯达克指数在过去三年分别累计上涨40%、73%、112%。AI板块贡献了美股大部分盈利和涨幅。美股“七姐妹”累积上涨280%左右,剔除“七姐妹”的标普其它成份指数涨幅有限。不过,每当美股创历史新高时,投资者对AI泡沫的担忧就会上升。当前AI是否存在泡沫?该如何投资?
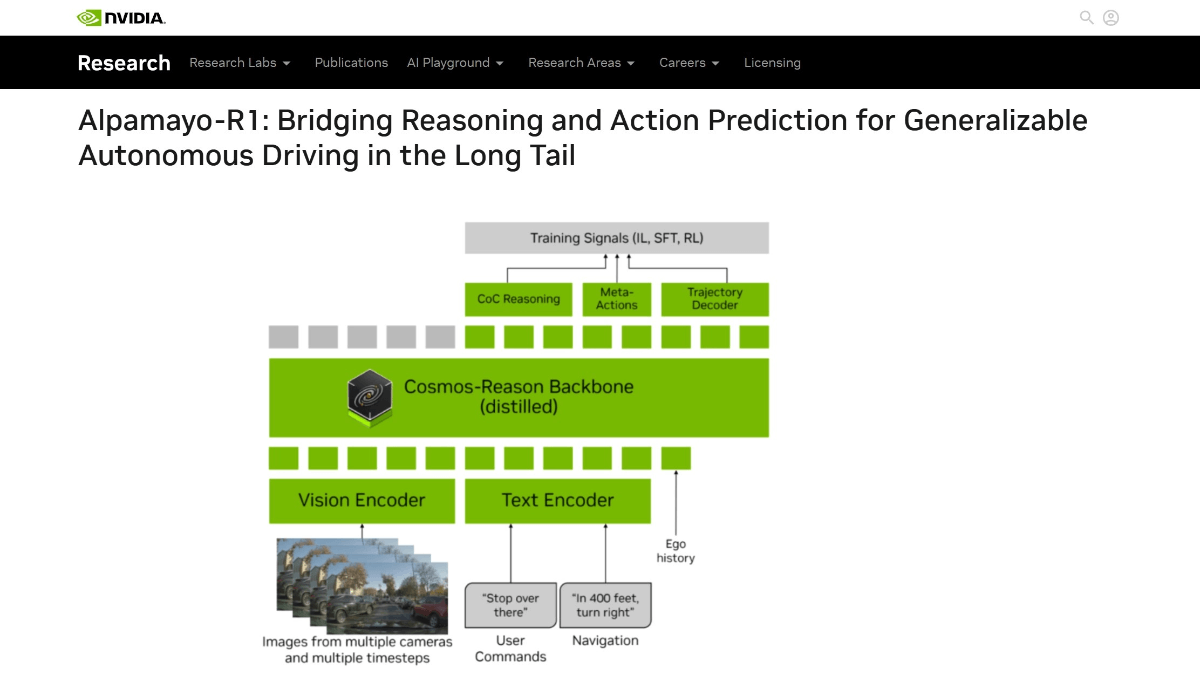
Alpamayo-R1是英伟达研发的具有推理能力的视觉-语言-行动(VLA)模型,专为提升自动驾驶在复杂场景中的决策能力设计。通过引入因果链推理机制,让车辆能像人类驾驶员一样分析场景因果关系(如“因前方有行人需减速”),而非单纯执行预设指令。模型采用多摄像头输入和轻量级编码技术降低计算成本,并通过强化学习优化轨迹规划,实测在长尾场景中使事故风险降低35%。创新点包括结构化因果标注数据集和模块化设计,支持实时推理延迟低于100毫秒。