HunyuanVideo-Foley - 腾讯推出的开源视频音效生成模型
HunyuanVideo-Foley 是腾讯混元团队开源的视频音效生成模型,支持为无声视频添加精准匹配的音效。模型基于大规模数据集训练,用多模态扩散变换器架构,结合表征对齐损失函数和音频VAE优化技术,能生成高质量、层次丰富的音效。模型适用短视频创作、电影制作、广告创意、游戏开发等场景,能显著提升内容的沉浸感和吸引力,让创作更高效、更专业。
HunyuanVideo-Foley 是腾讯混元团队开源的视频音效生成模型,支持为无声视频添加精准匹配的音效。模型基于大规模数据集训练,用多模态扩散变换器架构,结合表征对齐损失函数和音频VAE优化技术,能生成高质量、层次丰富的音效。模型适用短视频创作、电影制作、广告创意、游戏开发等场景,能显著提升内容的沉浸感和吸引力,让创作更高效、更专业。
MiniCPM-V 4.5 是面壁智能开源的 8B 参数多模态模型,基于 Qwen3-8B 和 SigLIP2-400M 构建,具备高效处理图像和视频的能力。在视觉 Token 消耗上表现出色,处理 180 万像素图像仅需 640 个视觉 Token,大大减少了计算资源消耗。模型在高刷视频理解方面表现突出,可接收 6 倍视频帧数量,达到 96 倍视觉压缩率,是同类模型的 12-24 倍。MiniCPM-V 4.5 支持多语言交互,可处理 30 多种语言,适用于多语言客服和翻译场景。文档处理能力也非常出色,能处理复杂图表和票据,支持手写体 OCR 和多语言文档解析。模型支持长思考和短思考的可控混合推理,可根据实际需求灵活调整推理速度和深度。
Gemini 2.5 Flash Image(代号nano banana)是谷歌推出的先进图像生成与编辑模型,能保持角色在不同场景中的一致性,支持通过自然语言进行精准图像编辑,如模糊背景、消除污渍等。模型结合 Gemini 的世界知识,能理解手绘图表并执行复杂指令。用户能通过 Google AI Studio 、Gemini API等平台使用模型,模型生成的图片带有隐形数字水印,便于识别 AI 创作内容。Gemini 2.5 Flash Image 为创意设计、广告营销、影视动画等领域带来强大的功能体验。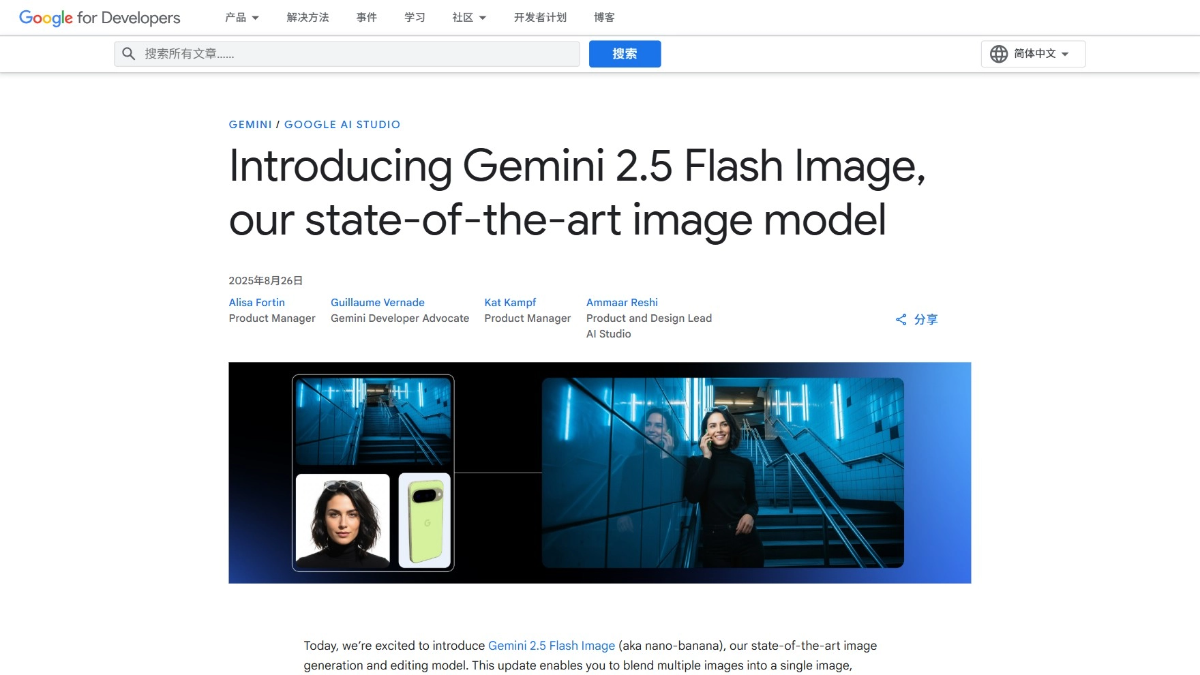
VibeVoice 是微软推出的新型文本到语音(TTS)模型。模型能生成多达 4 位不同说话者的对话式音频,支持长达 90 分钟的连续语音输出,突破传统 TTS 系统的长度限制。VibeVoice 生成的语音富有表现力,能根据文本内容产生带有情感和语调的语音,让对话更自然生动。VibeVoice支持多种语言的语音合成,能处理跨语言对话场景,生成的语音质量高,接近人类自然语音。VibeVoice 能应用在播客制作、有声读物、虚拟助手、教育和培训、娱乐和游戏等多个领域,为相关场景提供自然流畅的语音交互体验。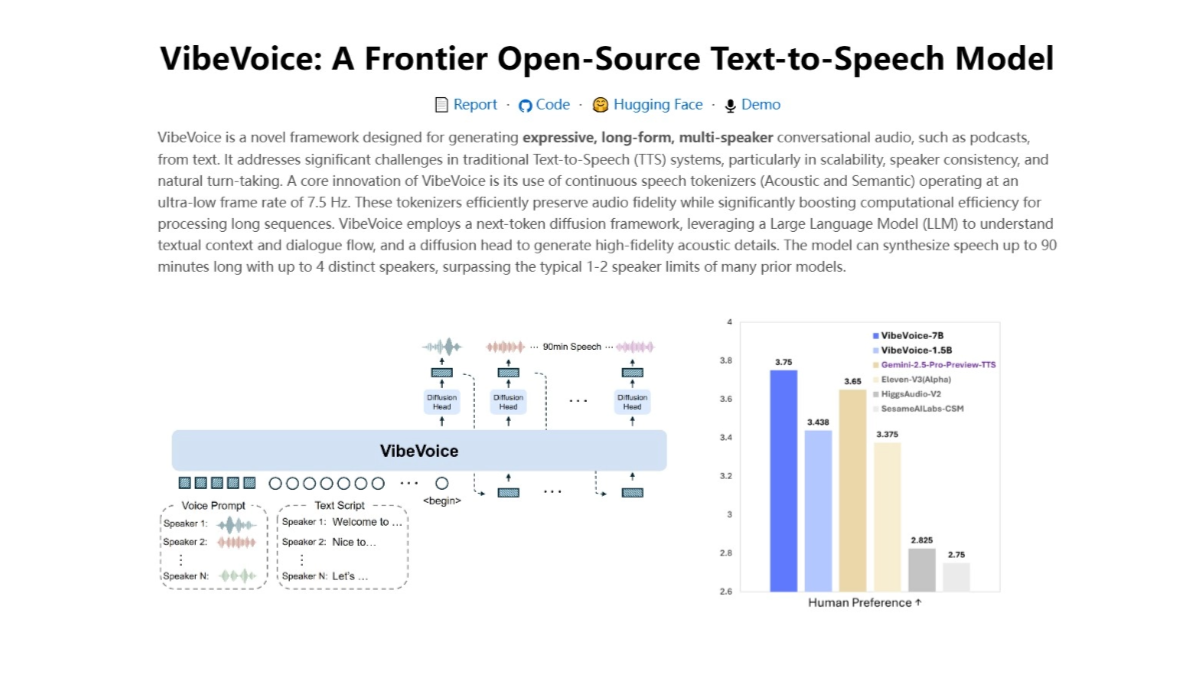
Grok 2.5是埃隆·马斯克旗下的xAI公司开源的人工智能模型。拥有2690亿参数,基于混合专家(MoE)架构,具有强大的性能和推理能力。模型在研究生级科学知识(GPQA)、通用知识(MMLU、MMLU-Pro)和数学竞赛(MATH)等测试中表现卓越,接近当前前沿水平。Grok 2.5的文件包含42个权重文件,总容量约500GB,需要至少8个显存超过40GB的GPU才能运行。xAI建议使用SGLang语言和最新版的SGLang推理引擎来运行该模型。在逻辑推理和代码生成方面表现出色,适合用于学术研究和解决复杂问题。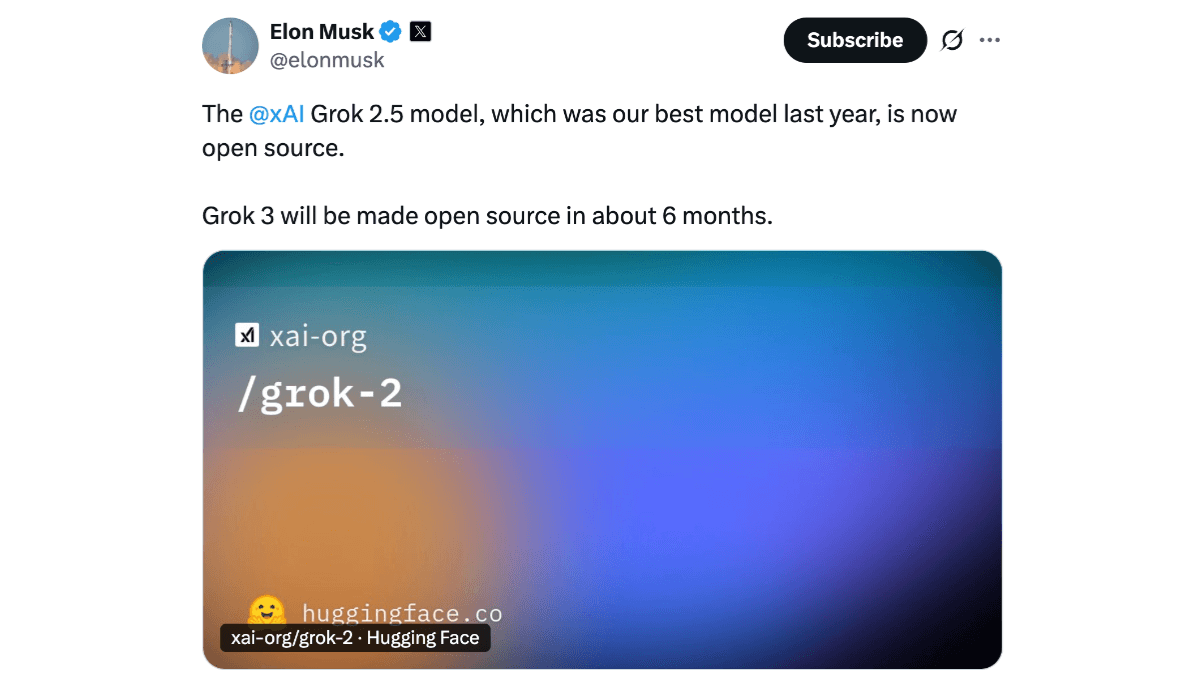
Klear-Reasoner 是快手推出的高性能推理模型,基于 Qwen3-8B-Base 进行开发。模型通过长思维链监督微调和强化学习训练,在数学和代码推理方面表现出色。Klear-Reasoner 的核心创新是 GPPO 算法,基于保留被裁剪的梯度信息,显著提升模型的探索能力和负样本的收敛速度。在 AIME 和 LiveCodeBench 等基准测试中,Klear-Reasoner 展现出卓越的性能,达到 8B 模型的顶尖水平。模型能解决复杂的数学问题,且能生成高质量的代码片段。Klear-Reasoner 广泛应用在教育、软件开发、金融科技等领域,为推理模型的发展提供宝贵的参考和复现路径。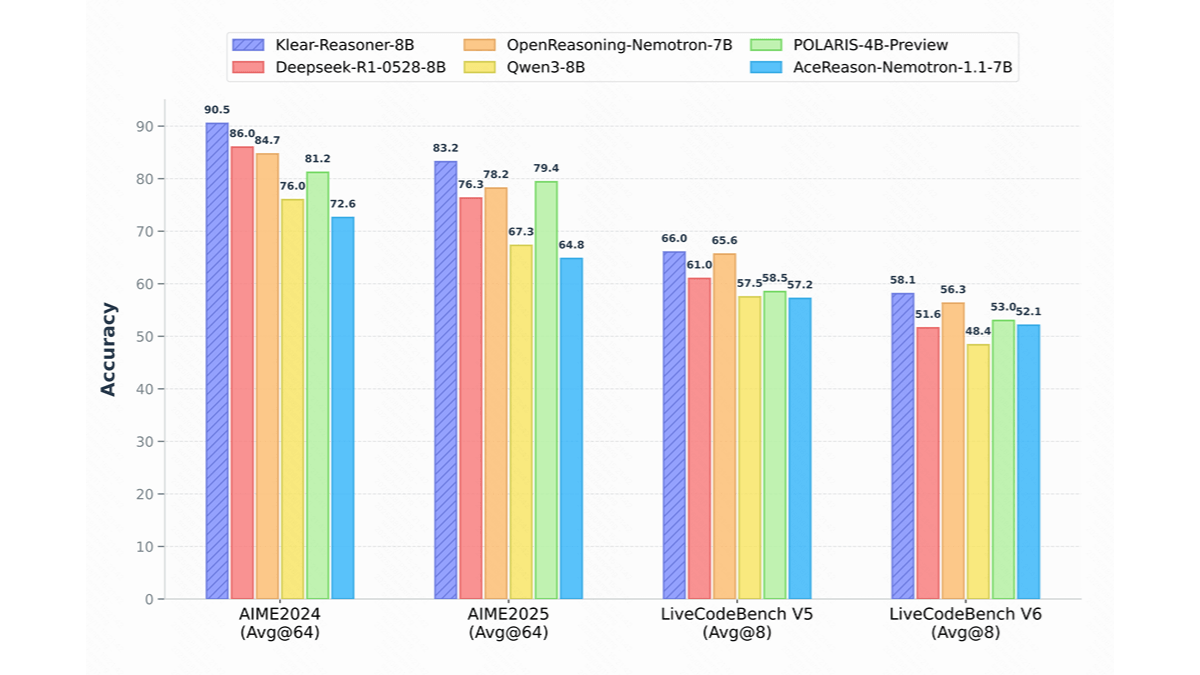
DeepSeek V3.1 是DeepSeek推出的最新开源 AI 模型,基于混合专家(MoE)架构,上下文窗口扩展至 128k,能处理更长的文本。模型在自然语言处理上表现出色,生成的创意文本生动有趣,回答问题时信息量大且语气自然。模型的编程能力显著提升,支持生成复杂度更高的代码,帮助开发者快速搭建框架。在数学和逻辑方面,模型能准确解答基础算术题,物理模拟效果更符合实际定律。DeepSeek V3.1的Base 版本已开源至 Hugging Face,能广泛应用在内容创作、编程辅助、教育和科学研究等领域。
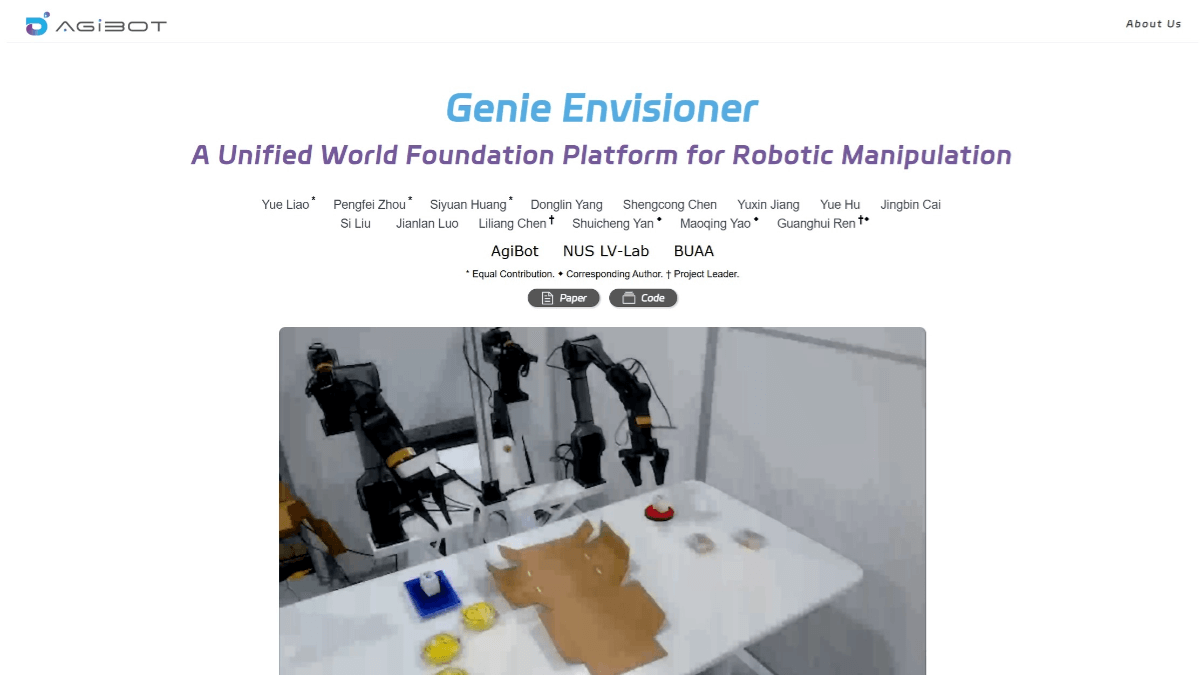
Genie Envisioner(GE)是智元机器人团队联合新加坡国立大学、北京航空航天大学等机构开发的机器人操作统一平台。通过“先想象,后行动”的方式,让机器人更好地理解和执行任务。GE的核心包括三个部分:GE-Base、GE-Act和GE-Sim。GE-Base是一个指令驱动的视频扩散模型,能捕捉机器人在真实世界中的交互动态。GE-Act基于GE-Base,将潜在的表示转化为可执行的动作轨迹,支持不同形态的机器人。GE-Sim是一个动作条件的神经模拟器,能生成高保真的模拟视频,用于训练和评估。