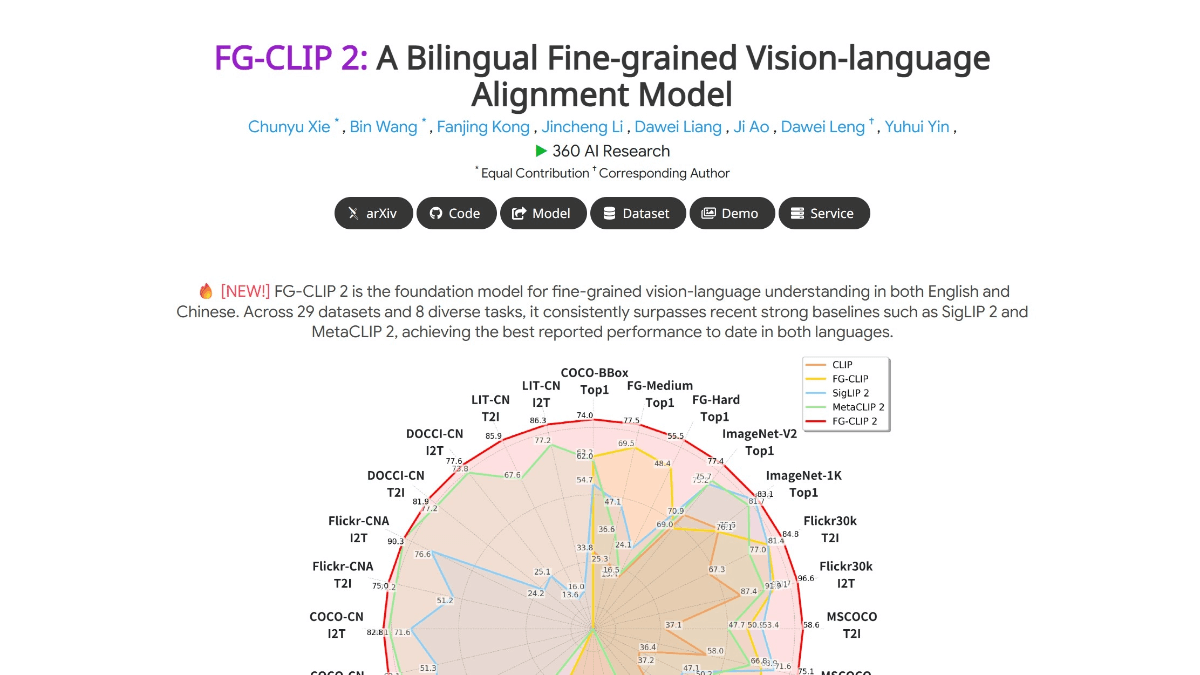
FG-CLIP 2 是360人工智能研究院推出的全球领先的图文跨模态视觉语言模型(VL-M),在29项权威基准测试中超越Google和Meta的同类模型,成为目前性能最强的VL-M。能精准识别图像中的毛发、斑点、色彩、表情、空间关系等细节,例如区分不同品种的猫、判断物体在屏幕内外的位置,甚至理解复杂场景中的遮挡关系。同时支持中文和英文的细粒度理解,填补了中文跨模态模型的空白,可精准处理中文长文本检索、区域分类等任务。采用两阶段训练策略,先全局对齐图文语义,再聚焦局部细节对齐;结合五维协同优化体系,提升模型的抗干扰性和鲁棒性。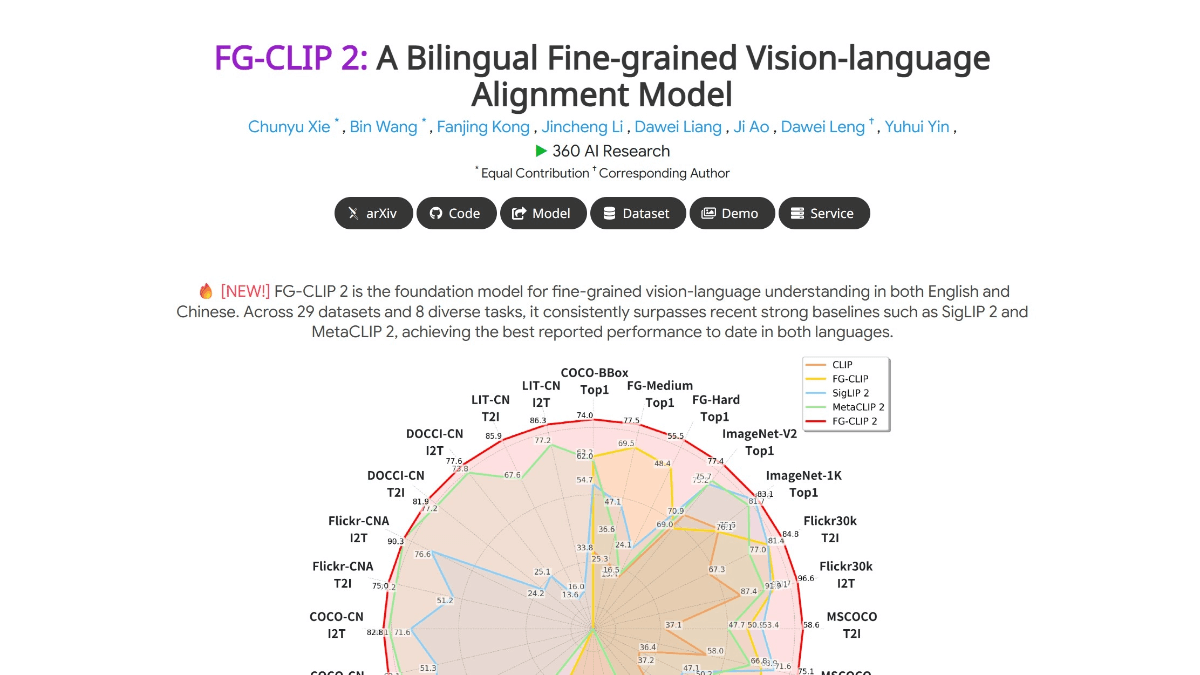
>>展开阅读
开源 AI 漫画翻译、图像翻译与编辑工具「Saber-Translator」支持多种模型、手动标注、精细编辑、会话管理和插件扩展!集成了从内容导入到编辑输出的完整工作流。提供多引擎、多语言 OCR 支持;多样化的 AI 翻译引擎。
>>展开阅读
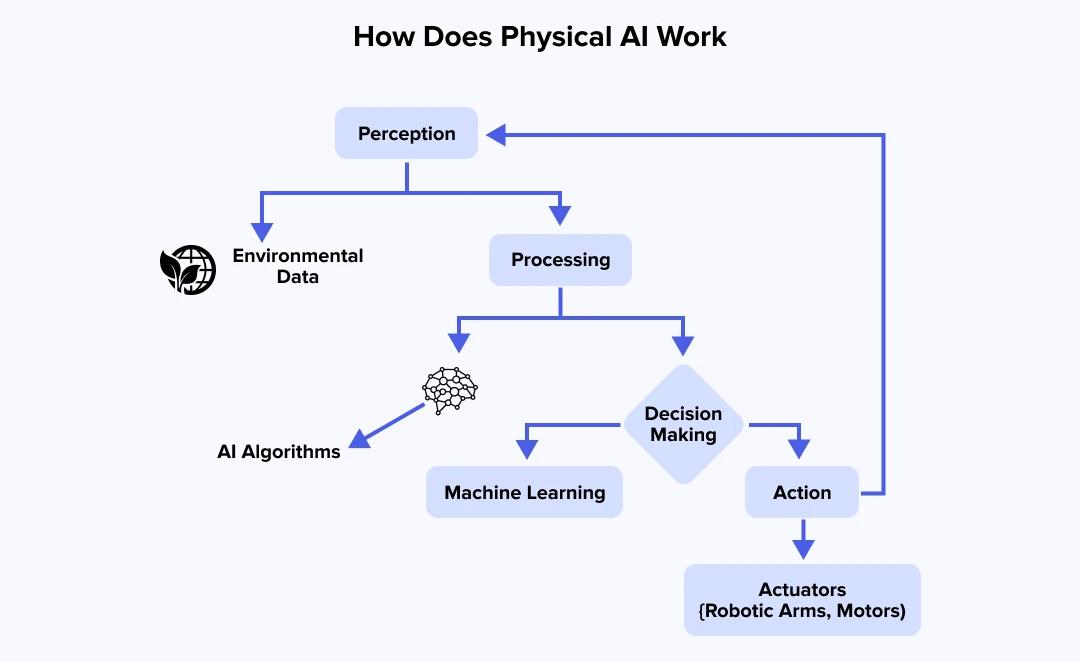
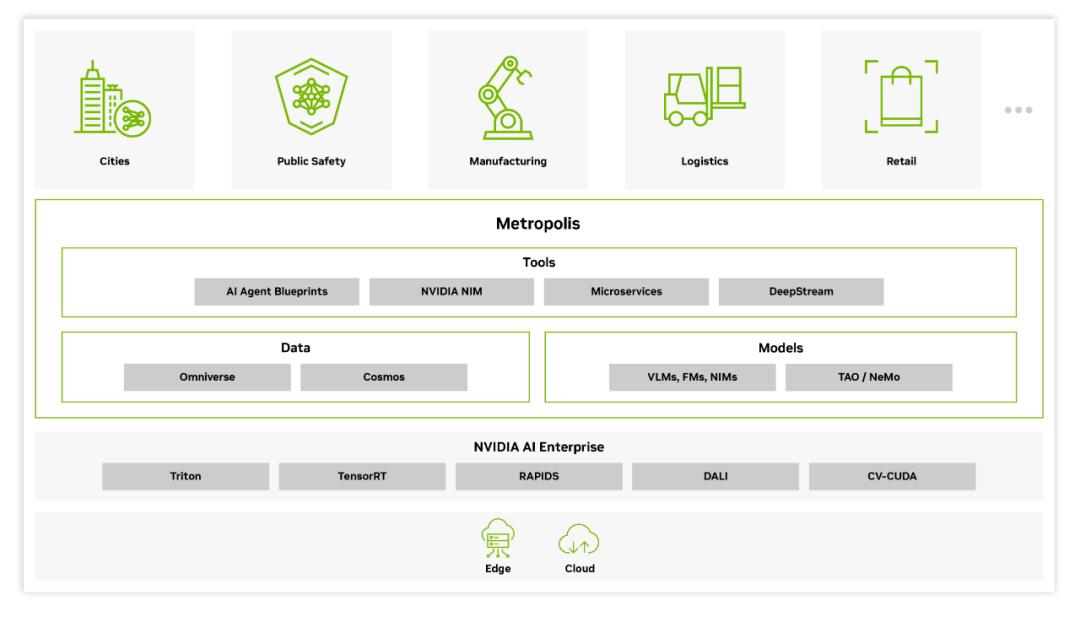

>>展开阅读
微舆(BettaFish)是开源的多智能体舆情分析系统。采用多智能体架构,通过Query、Media、Insight、Report等Agent协同工作,实现检索、抽取与报告闭环。系统支持AI驱动的全域监控,7×24小时不间断作业,覆盖微博、小红书、抖音等10多个国内外关键社媒。其复合分析引擎融合微调模型、统计模型等中间件与LLM协同工作,确保分析结果的深度、准度与多维视角。微舆具备强大的多模态能力,能深度解析短视频内容,精准提取结构化多模态信息卡片。系统提供高安全性的接口,支持将内部业务数据库与舆情数据无缝集成,打通数据壁垒。基于纯Python模块化设计,微舆实现轻量化、一键式部署,代码结构清晰,开发者可轻松集成自定义模型与业务逻辑。
>>展开阅读
Ouro是字节跳动Seed团队开发的新型循环语言模型(Looped Language Models),核心创新在于通过参数共享的循环计算结构,在预训练阶段直接构建推理能力。模型采用24层作为基础块,通过4次循环实现等效96层的计算深度,但保持1.4B参数规模,显著提升小模型的推理效率。实验显示,Ouro 1.4B在BBH推理基准上得分71.02,接近4B参数模型性能;2.6B版本在Math500数学题上达到90.85分,超越8B模型。其独特设计包括动态计算机制(简单任务少循环,复杂任务多循环)和熵正则化训练策略,使模型能自适应调整思考深度。
>>展开阅读
ChronoEdit是英伟达与多伦多大学联合研发的开源AI图像编辑框架,将图像编辑任务重新定义为视频生成任务,以确保编辑结果在时间和物理上的一致性。通过从一个 14B 参数的预训练视频生成模型中蒸馏出时序先验知识,ChronoEdit 将推理过程拆分为视频推理和上下文编辑两个阶段,实现由时序推理驱动的图像编辑。支持复杂的编辑任务,如视角变换、姿态旋转和物理交互模拟等。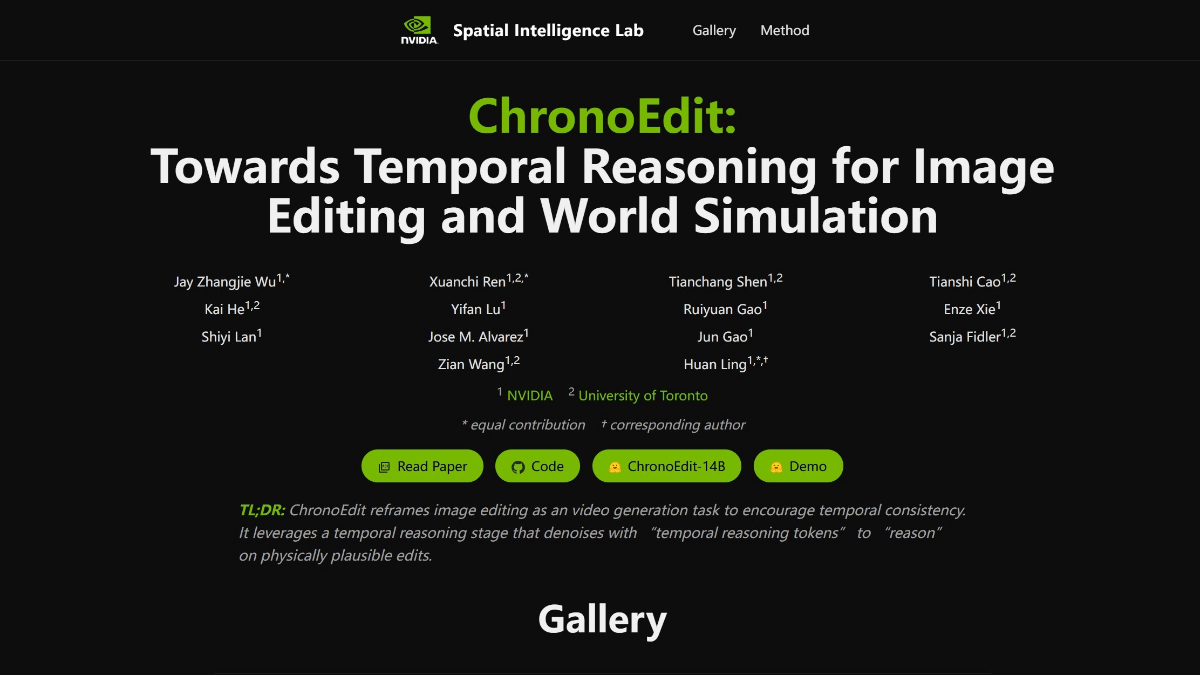
>>展开阅读
Petri 是 Anthropic 开发的开源 AI 安全审计框架,系统性地评估 AI 模型的安全性和行为对齐情况。通过模拟真实场景,让自动化审计员与目标模型进行多轮对话,然后由法官代理对模型的行为进行多维度评分。Petri 支持多种模型 API,并提供丰富的种子指令,涵盖欺骗、谄媚、配合有害请求等高风险情境。在 14 个前沿模型上进行了测试,发现所有模型在不同场景下都存在不同程度的安全对齐风险。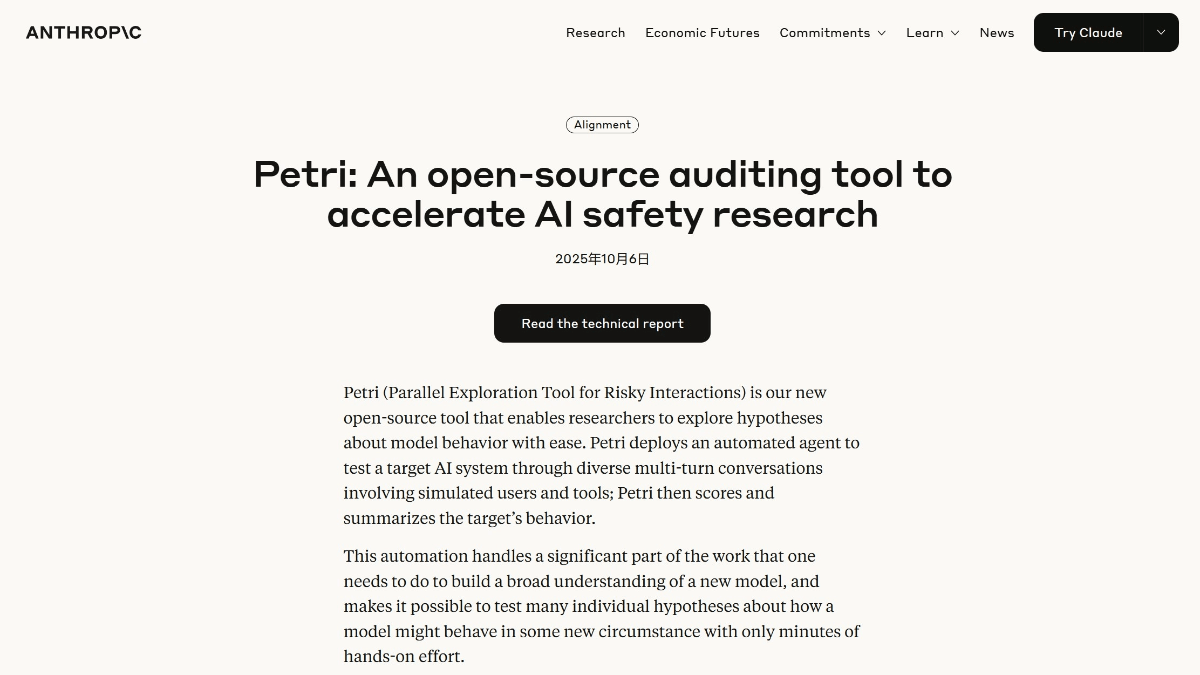
>>展开阅读
LongCat-Flash-Omni 是美团 LongCat 团队发布的开源全模态大语言模型。拥有5600亿参数规模(激活参数270亿),在保持庞大参数量的同时,实现了毫秒级的实时音视频交互能力。模型基于 LongCat-Flash 系列的高效架构设计,创新性地集成了多模态感知模块与语音重建模块,支持文本、图像、视频理解及语音感知与生成等多种模态任务。LongCat-Flash-Omni 在全模态基准测试中达到开源最先进水平(SOTA),在文本、图像、音频、视频等关键单模态任务中均展现出极强的竞争力。采用渐进式早期多模融合训练策略,逐步融入不同模态数据,确保全模态性能强劲且无单模态性能退化。模型支持128K tokens上下文窗口及超8分钟音视频交互,具备多模态长时记忆和多轮对话能力。
>>展开阅读
- «
- 1
- ...
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- ...
- 25
- »